AI
Better Exploiting Spatial Separability in Multichannel Speech Enhancement with an Align-and-Filter Network
|
IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP) is an annual flagship conference organized by IEEE Signal Processing Society. And ICASSP is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. It offers a comprehensive technical program presenting all the latest development in research and technology in the industry that attracts thousands of professionals. In this blog series, we are introducing our research papers at the ICASSP 2025 and here is a list of them. #2. Better Exploiting Spatial Separability in Multichannel Speech Enhancement with an Align-and-Filter Network (AI Center - Mountain View) #4. Text-aware adapter for few-shot keyword spotting (AI Center - Seoul) #8. Globally Normalizing the Transducer for Streaming Speech Recognition (AI Center - Cambridge) |
Introduction
Voice has played a vital role in our daily communications with family, friends and colleagues, as well as in interactions with our intelligent devices. With emerging mobile devices (smartphones, tablets), wearables (smartwatches, earbuds) and home appliances (fridges, robot cleaners), voice technologies will continue to enable more essential applications and enhance user experience. Along this path, the inevitable enemy, however, is the surrounding noise and interference encountered in our daily lives. Specifically, information carried by the speech signal could be severely lost at the receiver side in a noisy environment, causing difficulties in voice communication. Therefore, how to effectively cope with the environmental noise has been an essential issue for every voice processing technology to perform robustly in the real world.
Multichannel speech enhancement (SE) systems tackle this challenge by taking advantages of multiple microphone sensor signals to extract clean speech from noisy recordings. One of the leading techniques is spatial filtering (or beamforming), which applies a linear spatial filter to the multichannel (i.e., multi-microphone) noisy signals to separate noise and speech based their spatial characteristics. Mainstream deep learning-based approaches, e.g., [1][2], rely on the modeling power of neural networks, with a hope to directly model the noisy-to-clean speech mapping in one stage as shown in Figure 1 (a). Though demonstrating promising results over conventional signal processing methods, this type of one-stage modeling may lack explicit guidance on extracting useful spatial features, leading to reduced robustness in circumstances where the target speaker may be at arbitrary, unknown locations to the recording devices.
Instead of denoising the noisy signals in just one stage, conventional model-based, signal processing methods usually adopt a two-stage design. As shown in Figure 1 (b), in many classical algorithms [3][4], a key step is to spatially align the microphone signals in response to the target source’s direction of arrival before further spatial filtering process. This alignment step effectively localizes the target source by compensating for the temporal and level differences of the received target speech components among all microphones. As a result, with reduced spatial uncertainty of the target speech after the alignment stage, the subsequent filtering stage can more focus on extracting the clean speech components.
In this blog post, we focus on improving the robustness of deep learning-based multichannel SE systems against target speaker’s location uncertainty. Inspired by the “alignment-followed-by-filtering” principle from classical signal processing, we propose Align-and-Filter network (AFnet) robust to spatially uncertain speaker scenarios, featuring a two-stage deep network design shown in Figure 1 (c). The key is to leverage the relative transfer functions (RTFs) [3][4] that encode meaningful spatial information of the speech to supervise the learning of spatial alignment with respect to the speaker location. Through explicitly injecting spatial information using RTFs during model training, AFnet effectively captures interpretable spatial characteristics of speech signals from spatially diverse data to better separate speech from interfering signals and background noise.

Figure 1. Illustration of different multichannel SE systems. (a) Typical deep learning-based methods directly model the noisy-to-clean speech mapping. (b) Classical signal processing approaches perform SE as two sub-tasks. (c) Our framework models both alignment and filtering processes with deep networks, by supervising the spatial alignment process using relative transfer functions (RTFs) as the learning target.
Background
1. Problem Formulation
We consider the multichannel SE problem as follows.
Scenario: one desired speech source and several interfering noise signals in a reverberant environment
Signal Model: time-frequency domain processing using the short-time Fourier transform (STFT) assuming an additive noise model:
Let f,t stand for the frequency and time frame indexes (total: F bins and T frames), the i-th microphone noisy signal STFT Xi∈CF×T of an N-microphone array can be written as:

where Si≜Hi⊙S0∈CF×T is the speech component received by microphone i, ⊙ denotes element-wise product, Hi∈CF×T is the acoustic transfer function between the speech source S0∈CF×T and microphone i, and Vi∈CF×T is the noise component captured by microphone i
Goal: to recover the speech component Sr∈CF×T at a reference microphone r∈{1,...,N} given the N noisy signals Xi,...,XN
2. Spatial Filtering in STFT Domain
Multichannel SE systems usually perform spatial filtering, or beamformig, through proper linear combination of the microphone signals to obtain the enhanced signal S ̂∈CF×Tas:

where Wi∈CF×T is the set of beamformer filters of microphone i.
To derive Wi's, traditional signal processing algorithms are majorly designed based on an “align-then-filter” concept: employing a spatial alignment stage of target speech before the noise filtering step by estimating the temporal (phase) and level (magnitude) differences among the received speech components Si's. However, the notion of such spatial alignment is often overlooked in current SE deep network designs, potentially leading to suboptimal robustness against spatial uncertainty of target speech.
Proposed Method
1. Align-and-Filter Network (AFnet)
Our approach interprets multichannel SE process as:

which decomposes the beamformer weights Wi in (2) into two entities, spatial alignment (Ai) and filtering (Fi) units. This then suggests a sequential masking scheme in (3) that we first perform alignment on the input signals followed by the filtering. The entire process is realized by concatenating two deep net modules, Align Net and Filter Net, as depicted in Figure 2. The first module (Align Net) estimates a set of alignment masks Ai to be multiplied with the input noisy STFTs Xifor spatial alignment with respect to the target speech. The second module (Filter Net) estimates another set of filtering masks Fito linearly combine the N (roughly) aligned signals Zi for cleaning up noises. During training, AFnet is supervised to perform both spatial alignment and filtering processes explicitly using the associated alignment and reconstruction losses introduced next.
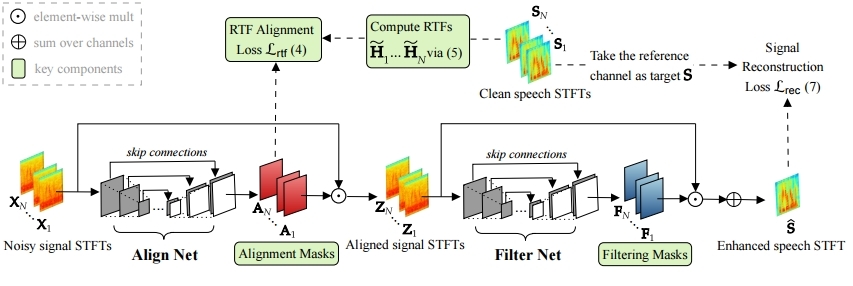
Figure 2. The proposed AFnet based on the “align-then-filter” principle for better capturing spatial characteristics of speech data rich in directional variety. We highlight (in green) the key components that contribute to our SE improvement: RTF-based supervision for spatial alignment and sequential masking design.
2. Learning the Alignment Process
The Align Net aims to perform spatial alignment with respect to the target speech given the input noisy signals. To this end, we utilize the speech relative transfer function (RTF) as the supervised learning target for alignment. The RTF is a useful and widely adopted representation of cross-channel differences in conventional model-based beamformers [3][4]. With speech RTFs, one can easily infer the spatial relation between the speech source and microphones. We thus propose the optimization for training the Align Net by:

where the alignment mask Ai estimates the speech RTF H ̃i defined between microphone i and reference microphone r:

where ⊘ denotes the element-wise division. Eq. (5) indicates that to get speech RTFs as the learning targets in (4) for training, the actual acoustic transfer functions Hi’s are not needed and only using clean speech signals Si’s suffices. In our work, we take advantages of RTFs to inject spatial information into deep network learning.
Note that ideally, when Ai=H ̃i we get the perfectly aligned signals:

∀i=1,...,N, where V ̃i≜H ̃i⊙V_i is the modified noise component. In (6), we see that each Zi now contains a channel-independent clean speech term Sr. This can be interpreted as “spatially aligning” inputs with respect to the target speech, as now all N channels have the same speech component and the dependency on the speech location is removed. From the geometry viewpoint, it means that regardless of the direction that a speech signal is actually coming from, after alignment all the speech signals will be perceived as coming from a constant direction (i.e., no temporal and level differences) in the case of far-field, anechoic setting. As a result, it helps reduce spatial uncertainty, alleviating the burden of the later spatial filtering module.
3. Learning the Filtering Process
The Filter Net module aims to extract the clean speech from the background noise through a spatial filtering process like a beamformer. It outputs the filtering masks Fi to spatially filter the aligned signals Zi. This way, it can concentrate on learning to extract the desired speech component from the more spatially constant multichannel signals output by Align Net. As the goal is to recover the clean speech at the final output, we train the entire AFnet model by minimizing the signal reconstruction loss:

where we have chosen to use the combined power-law compressed mean-squared-error loss with β=0.3 and c=0.3, following [5].
4. Architecture and Model Training
We adopt a two-step training scheme for AFnet: i) pre-train the Align Net by minimizing ℒrtf (4) until decent RTF alignment is learned; ii) train the entire network to jointly learn Filter Net parameters while fine-tuning Align Net by minimizing ℒrec (7). We adopt the same architecture for both Align Net and Filter Net based on modifying the complex U-Net [6].
Experiments
1. Dataset and Experimental Setup:
To study multichannel SE with spatially diverse speech data, we follow the common practice in multichannel SE works to utilize computational tools for synthesizing multichannel noisy signals. Specifically, we leverage the AVSpeech dataset [7], using only the audio portion as clean speech corpus. We utilize the Pyroomacoustics [8] simulator to obtain room impulse responses (RIRs) for generating the multichannel data, encompassing a variety of target speech locations, noise types and locations, signal-to-noise ratios and reverberation conditions. For evaluation, we consider three commonly seen metrics: PESQ (Perceptual Evaluation of Speech Quality), STOI (Short-Time Objective Intelligibility) and SSNR (Segmental Signal-to-Noise Ratio), where a higher score indicates better SE performance for all three metrics.
2. Experimental Results
Benefits of RTF-Aware Spatial Alignment: We demonstrate the advantages of utilizing the proposed RTF alignment during training for AFnet by comparing with the model trained without the RTF loss. We also compare with the RTF-aware model where in the first training step we exclude phase alignment by forcing Align Net to approximate only the magnitude of RTFs, i.e., minimizing ℒrtf,mag-only=1/N ∑(i=1)N‖|Ai|-|H ̃i|)‖F2 instead of (4), to observe the role of phase components which correlate more with the sound source location. In Figure 3, we compare “w/o RTF loss”, “w/ RTF loss (mag-only)” and “w/ RTF loss” results for AFnet. First, we see that “w/ RTF loss” (green bars) the model can achieve considerable improvements in all settings over “w/o RTF loss” (blue bars), suggesting the advantages of performing spatial alignment. Second, we also observe the importance of phase alignment: without aligning phase the SE performance does not necessarily improves with more microphones used, as observed in both “w/o RTF loss” (blue bars) and “w/ RTF loss (mag-only)” (orange bars) cases. In contrast, the performance of “w/ RTF loss” (green bars) monotonically increases with more microphones included, suggesting the model indeed exploits spatial separability for desirable spatial filtering behavior.

Figure 3. SE comparison of different RTF alignment schemes for AFnet training. We see that “w/ RTF loss” (green bars) achieves considerable improvements in all settings, suggesting the advantages of performing spatial alignment.
Visualizing the Learned Alignment Masks: To provide further analysis for alignment, we visualize the distributions of the estimated alignment masks for the 8-mic case via the t-SNE analysis. To this end, we feed noisy samples associated with speech sources positioned at three different locations (labeled as loc 1, loc 2, loc 3 in Figure 4) to the AFnet model well-trained with RTF loss, and obtain the corresponding alignment masks for each sample. The same procedure is also done for the AFnet model trained without RTF loss. From Figure 4, it can be seen that RTF-aware training results in more separate clusters of speech signals coming from the three different locations than normal training, suggesting that RTF supervision helps exploit more interpretable spatial features for multichannel SE.

Figure 4. t-SNE of learned alignment masks for speech signals coming from three different locations (loc 1, loc 2, loc 3). AFnet trained with RTF alignment loss supervision results in separate clusters, corresponding to successively learned spatial separability.
Generalizability to Unseen and Dynamic Acoustic Environments: We have also observed that the utilization of RTF alignment could improve generalization of the model. To see that, we present in Table 1 the SE results of the 4-mic AFnet on test data representing i) unseen room configurations and ii) time-varying target speech location scenarios. For unseen rooms, we again utilize Pyroomacoustics to generate test samples from three different room sizes which are different from the training room dimensions. We also generate another set of test data in which during an utterance the RIRs are changed from one set to another to emulate speaker movements. From the table we see show that with RTF alignment, AFnet generalizes better to unseen rooms and robustly tackles dynamic target locations even though it has not observed any changing RIR data during training, indicating that inter-channel spatial and directional features are effectively captured by the model.

Table 1. Generalization of the proposed RTF-based spatial alignment to unseen and dynamic acoustic environments.
Visualization of SE Outcomes: Finally, we present SE examples to facilitate qualitative comparison between AFnet and one-stage models of Figure 1 (a). For the latter, we use as an example the AFnet model without the sequential masking scheme applied, i.e., only estimating the beamformer weights Wi at the W-shaped network output which are directly multiplied with input Xi as (2). We refer to this alignment-unaware model as “W-Net” which is of the same size as the AFnet. The corresponding waveforms and spectrograms are presented in Figure 5 where the advantages of AFnet by exploiting spatial separability with the proposed alignment schemes can be clearly observed.
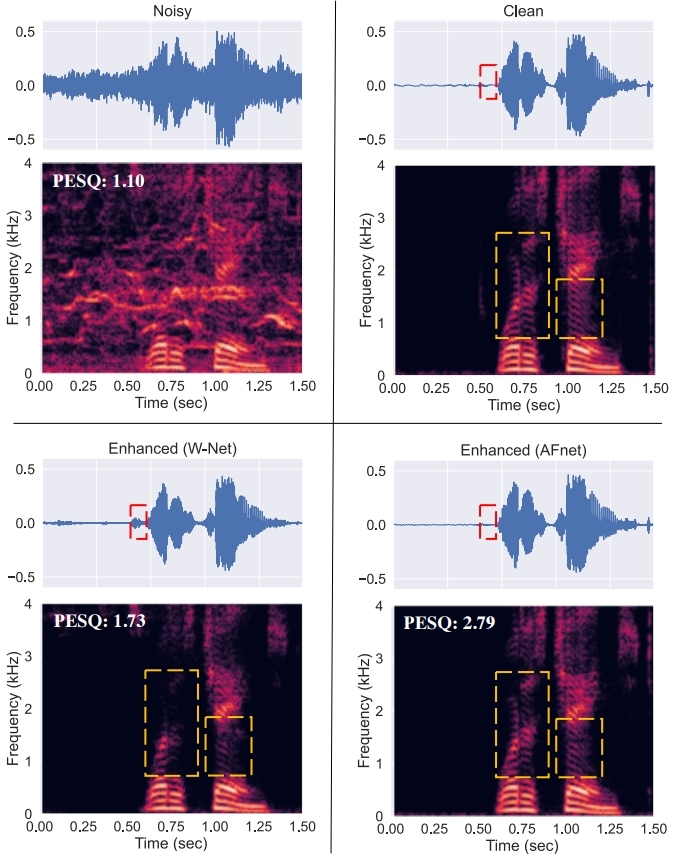
Figure 5. Comparing the waveforms of W-Net (an alignment-unaware model) and AFnet in the 8-mic setting, we can see that AFnet successfully removes the noise-only segment in the beginning of the utterance while W-Net fails to, as indicated in the red boxes. By inspecting the spectrograms, we notice that some detailed speech structures are highly distorted with W-Net, while AFnet preserves more speech structures, as marked by yellow boxes.
Conclusion
In this blog post, we presented AFnet, a multichannel SE deep learning framework that exploits the “align-then-filter” notion to handle speech sources with spatial uncertainty by leveraging the RTF, an essential component in many signal processing-based algorithms. Our findings suggest that alignment indeed plays an important role in deep learning-based approaches, especially for spatially diverse speech scenarios. More broadly, our work suggests that it would be beneficial to consider such spatial alignment aspect when developing advanced multichannel SE systems for various voice-driven technologies.
Link to the paper
https://ieeexplore.ieee.org/abstract/document/10890175/
References
[1] Y. Yang, C. Quan, and X. Li, “McNet: Fuse multiple cues for multichannel speech enhancement,” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), 2023.
[2] D. Lee and J.-W. Choi, “DeFT-AN: Dense frequency-time attentive network for multichannel speech enhancement,” IEEE Signal Process. Lett., vol. 30, pp. 155–159, 2023.
[3] S. Gannot, D. Burshtein, and E. Weinstein, “Signal enhancement using beamforming and nonstationarity with applications to speech,” IEEE Trans. Signal Process., vol. 49, no. 8, pp. 1614–1626, 2001.
[4] I. Cohen, “Relative transfer function identification using speech signals,” IEEE Trans. Speech Audio Process., vol. 12, no. 5, pp. 451–459, 2004.
[5] S. Braun and I. Tashev, “A consolidated view of loss functions for supervised deep learning-based speech enhancement,” in Proc. Int. Conf. Telecomm. Signal Process. (TSP), 2021, pp. 72–76.
[6] H.-S. Choi, J.-H. Kim, J. Huh, A. Kim, J.-W. Ha, and K. Lee, “Phase-aware speech enhancement with deep complex U-Net,” arXiv preprint arXiv:1903.03107, 2019
[7] A. Ephrat et al., “Looking to listen at the cocktail party: A speaker-independent audio-visual model for speech separation,” ACM Trans. Graphics, vol. 37, no. 4, pp. 109:1–109:11, 2018.
[8] R. Scheibler, E. Bezzam, and I. Dokmanic ́, “Pyroomacoustics: A Python package for audio room simulation and array processing algorithms,” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), 2018.

